I am ready for a long road flight for work with a week- or months-long projects.
We’ve generated data for training across many verticals:
How we do it
We produce high volume lookalike data (labeled or not); use your data to test it
Nurdlized Datasets
We produce high volume lookalike data (labeled or not); use your data to test it
Nurdlized Datasets
We detect ideal data clusters and what data is missing for your use-case
Data Gap Analysis
We detect ideal data clusters and what data is missing for your use-case
Data Gap Analysis
We compare yours with our pre-labelled LLM data vault
Nurdle Data Overlay
We compare yours with our pre-labelled LLM data vault
Nurdle Data Overlay
Yours or ours - as few as 50 rows
Real Data Sample
Yours or ours - as few as 50 rows
Real Data Sample
We produce high volume lookalike data (labeled or not); use your data to test it
Nurdlized Datasets
We detect ideal data clusters and what data is missing for your use-case
Data Gap Analysis
We compare yours with our pre-labelled LLM data vault
Nurdle Data Overlay
Yours or ours - as few as 50 rows
Real Data Sample
The question we hear more than any other seems pretty straight-forward on the surface... until you actually try to generate the size and variety of human-quality conversational data required for fine-tuning and model training.
NurdleGPT was built from one of the world’s largest data vaults of human-to-human text, chat, ratings, and post communications, giving it a significant advantage in generating unstructured text that is almost identical to how people actually communicate with one another.
NurdleGPT was built from one of the world’s largest data vaults of human-to-human text, chat, ratings, and post communications, giving it a significant advantage in generating unstructured text that is almost identical to how people actually communicate with one another.
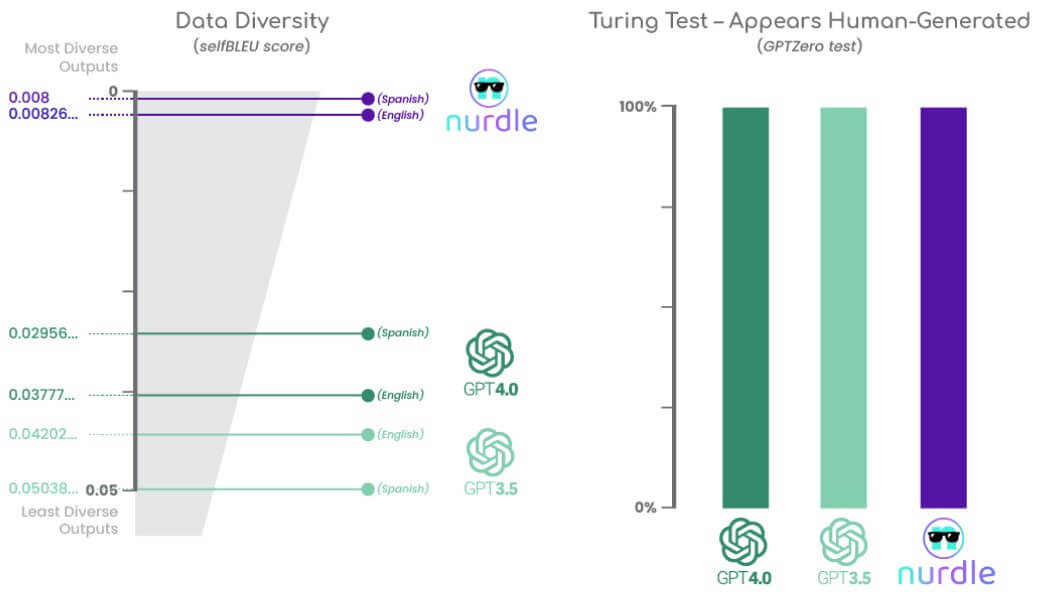
5x more diverse unstructured text data than ChatGPT — with the same quality
Why not just use ChatGPT to make synthetic datasets?
When humans chat, post, and message each other in real life, they’re short and to-the-point. We use shortcuts like bad punctuation, mis-spelled words, and slang – or even emojis – to replace whole words and sentences.
Large Language Models like ChatGPT are a bit more verbose, which is not helpful if you’re training a model to detect behaviors in real human communications.
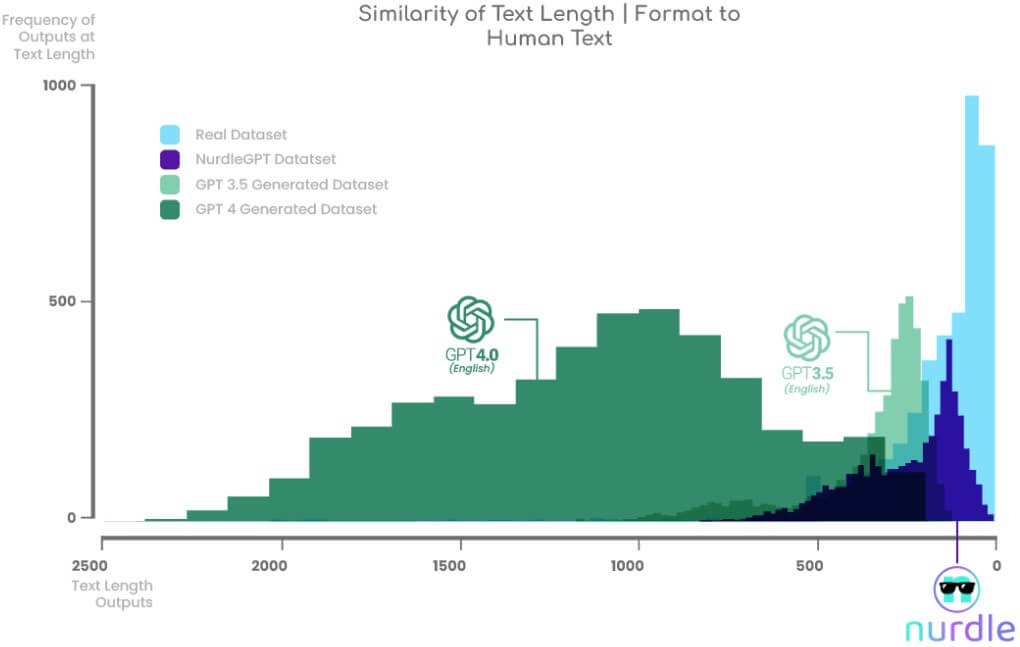
NurdleGPT was built from hundreds of terabytes of real human-to-human communications so its output looks, sounds, and is even the same format and length as real human text.
Large Language Models like ChatGPT are a bit more verbose, which is not helpful if you’re training a model to detect behaviors in real human communications.
NurdleGPT was built from hundreds of terabytes of real human-to-human communications so its output looks, sounds, and is even the same format and length as real human text.
The most similar text structure to human-generated text
Humans don’t really chat like ChatGPT
Cheaper is Better. The future of AI is small, specialized LLMs that are cheap to run
ChatGPT is great for prototyping an AI project, but the compute costs to run it is 100 - 500 times more expensive than smaller LLMs that have been fine-tuned for specific use-cases.
This example by AnyScale shows performance differences for a specific task (summarizing emails) before and after task-specific fine-tuning.
Train open-source LLMs quickly and inexpensively with 100% privacy-safe Nurdle data.
This example by AnyScale shows performance differences for a specific task (summarizing emails) before and after task-specific fine-tuning.
Train open-source LLMs quickly and inexpensively with 100% privacy-safe Nurdle data.

Why Nurdle?
Methodology
1. Dataset Generation
We generated a dataset consisting of 5,000 rows of customer-specific data. This dataset was carefully crafted to capture the diverse range of language patterns and topics relevant to our customer's needs.
2. Fine-Tuning and Comparison
We utilized NurdleGPT, a second-generation Lookalike Data generator, along with two first-generation synthetic data generators, to create datasets for comparison. Additionally, we used a subsampled dataset of 5,000 rows for fine-tuning purposes.
3. Evaluation
Our evaluation process involved analyzing the results for precision and recall with experienced data labeling teams. We also employed metrics such as Self-BLEU scores and Earth Mover's Distance (EMD) to assess the diversity and distribution matching of the generated data.
4. Cost Analysis
Finally, we conducted a cost analysis to compare the expenses associated with each approach. This included estimating the cost per 5,000 rows of synthetic data generated by different models.
We generated a dataset consisting of 5,000 rows of customer-specific data. This dataset was carefully crafted to capture the diverse range of language patterns and topics relevant to our customer's needs.
2. Fine-Tuning and Comparison
We utilized NurdleGPT, a second-generation Lookalike Data generator, along with two first-generation synthetic data generators, to create datasets for comparison. Additionally, we used a subsampled dataset of 5,000 rows for fine-tuning purposes.
3. Evaluation
Our evaluation process involved analyzing the results for precision and recall with experienced data labeling teams. We also employed metrics such as Self-BLEU scores and Earth Mover's Distance (EMD) to assess the diversity and distribution matching of the generated data.
4. Cost Analysis
Finally, we conducted a cost analysis to compare the expenses associated with each approach. This included estimating the cost per 5,000 rows of synthetic data generated by different models.
Methodology
1. Dataset Generation
We created datasets with NurdleGPT and ChatGPT, each comprising 5,000 rows of synthetic text data, aiming to mimic real human-to-human communications.
2. Text Structure Analysis
We assessed the text structure similarity to human-generated text by analyzing the output of both models, considering shortcuts, punctuation, misspellings, slang, emojis, and overall clarity.
3. Comparison Metrics
We used metrics like Self-BLEU scores and Earth Mover's Distance (EMD) to gauge the resemblance between synthetic data from NurdleGPT and ChatGPT and real human-generated text, aiming for lower Self-BLEU scores and closer EMD values to the gold standard.
4. Cost Analysis
We also compared the expenses of generating synthetic data using NurdleGPT versus ChatGPT, factoring in input/output token costs and the total cost per 5,000 rows of synthetic data.
We created datasets with NurdleGPT and ChatGPT, each comprising 5,000 rows of synthetic text data, aiming to mimic real human-to-human communications.
2. Text Structure Analysis
We assessed the text structure similarity to human-generated text by analyzing the output of both models, considering shortcuts, punctuation, misspellings, slang, emojis, and overall clarity.
3. Comparison Metrics
We used metrics like Self-BLEU scores and Earth Mover's Distance (EMD) to gauge the resemblance between synthetic data from NurdleGPT and ChatGPT and real human-generated text, aiming for lower Self-BLEU scores and closer EMD values to the gold standard.
4. Cost Analysis
We also compared the expenses of generating synthetic data using NurdleGPT versus ChatGPT, factoring in input/output token costs and the total cost per 5,000 rows of synthetic data.

Justin Davis
Co-Founder and CEO
"Nurdle has been used for 6 years by Spectrum Labs to parse billions of online human interactions.
We've used Nurdle data to moderate content for Riot Games, Grindr, The Meet Group, Together Labs, and other gaming, dating, and social media platforms."
We've used Nurdle data to moderate content for Riot Games, Grindr, The Meet Group, Together Labs, and other gaming, dating, and social media platforms."







FAQ
Sorry, but no! Our core product is the synthetic data we generate, which will come to you labeled and formatted for training. Once we’re working together we’d be happy to advise you on other labeling solutions for your historical data.
In the case of Nurdle, it’s better! Our data will be human-quality and sound like real conversations, however we can tailor it to the specific gaps you’re trying to improve within your model. Your bot does the friendly persona really well but comes up short on witty? We’ll generate those witty messages and hand them to you pre-labeled and formatted to your liking. What’s better than that?!
Nurdle? Hours! Not weeks or months like other solutions out there.
Unstructured data, especially conversational data, is harder to get your hands on. However, at Nurdle we have unique expertise in unstructured text from the trillions of conversations we’ve collected, labeled, and stored over the last 6 years from our previous company that we successfully exited.
Yes! The trillions of data we mentioned in the last FAQ? That’s global conversational data so it enables us to understand and train in many languages, dialects, and slangs all over the world. We’ll generate your data primarily in the language of your choice, and then translate it into your language of preference after that (so you can gut check the quality in your preferred language!)
Not at this time, but it’s on the roadmap! For now, unstructured, conversational text is our focus.