I am ready for a long road flight for work with a week- or months-long projects.
Fine-Tuning Data
Custom, high-quality, privacy-compliant datasets at massive scale that you can afford
Use Custom Nurdle Datasets for
LLM Instruction Tuning & Reinforcement Learning
Generative LLMs (Chat & semantic search)
RLHF (Reinforcement Learning from Human Feedback) is the most effective way to train LLMs to behave within policy... but new data science techniques show that AI-created datasets can be just as effective - and far less expensive - to deploy.
Fine-tune your chatbot for brand or character voice or for product, industry or brand expertise. Fine-tune enterprise AI search with domain-specific expertise so it knows what you mean... even when you’re not quite sure how to ask correctly.
Use Custom Nurdle Datasets for
Create a brand voice for your AI chat from persona-specific custom fine-tuning data
Amp up performance, steer your LLM with RLAIF and build privacy-safe open-source LLMs faster and easier
Supplement your model's performance with custom data to improve performance on a specific ability
Cold-Start Problem
Fine-tune your LLM
Improve specific capabilities



The question we hear more than any other seems pretty straight-forward on the surface... until you actually try to generate the size and variety of human-quality conversational data required for fine-tuning and model training.
NurdleGPT was built from one of the world’s largest data vaults of human-to-human text, chat, ratings, and post communications, giving it a significant advantage in generating unstructured text that is almost identical to how people actually communicate with one another.
NurdleGPT was built from one of the world’s largest data vaults of human-to-human text, chat, ratings, and post communications, giving it a significant advantage in generating unstructured text that is almost identical to how people actually communicate with one another.
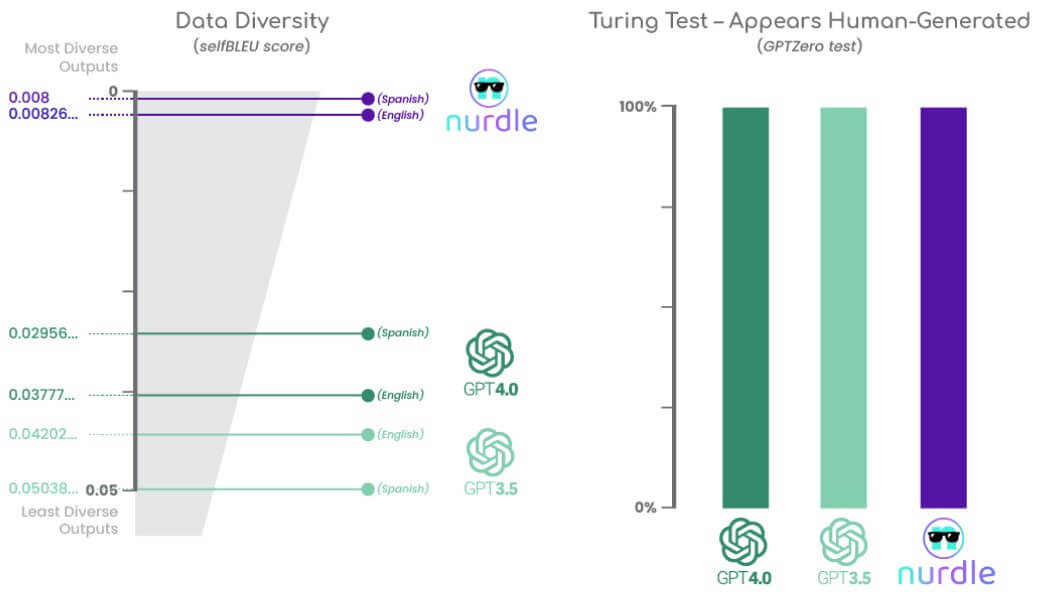
5x more diverse unstructured text data than ChatGPT — with the same quality
Why not just use ChatGPT to make synthetic datasets?
When humans chat, post, and message each other in real life, they’re short and to-the-point. We use shortcuts like bad punctuation, mis-spelled words, and slang – or even emojis – to replace whole words and sentences.
Large Language Models like ChatGPT are a bit more verbose, which is not helpful if you’re training a model to detect behaviors in real human communications.
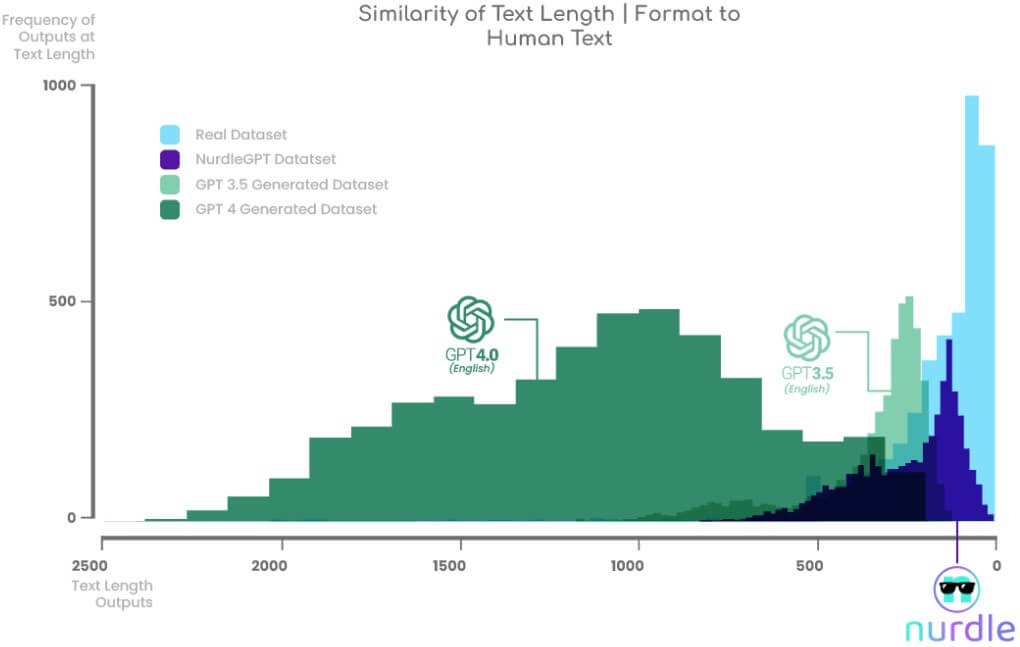
NurdleGPT was built from hundreds of terabytes of real human-to-human communications so its output looks, sounds, and is even the same format and length as real human text.
Large Language Models like ChatGPT are a bit more verbose, which is not helpful if you’re training a model to detect behaviors in real human communications.
NurdleGPT was built from hundreds of terabytes of real human-to-human communications so its output looks, sounds, and is even the same format and length as real human text.
The most similar text structure to human-generated text
Humans don’t really chat like ChatGPT
F1 Score
Human Data
92% Accuracy of Human Data — At 40% of the Cost
Nurdle Data
Gretel
Mostly AI
Compared to Human
Data Scientist Prep Time
Cost / 100k Rows
78.5%
100%
160 hr
$10000
72.1%
92%
40 hr
$4000
65%
82%
80 hr
$33
50% (random noise)
63%
80 hr
$1
Cheaper is Better. The future of AI is small, specialized LLMs that are cheap to run
ChatGPT is great for prototyping an AI project, but the compute costs to run it is 100 - 500 times more expensive than smaller LLMs that have been fine-tuned for specific use-cases.
This example by AnyScale shows performance differences for a specific task (summarizing emails) before and after task-specific fine-tuning.
Train open-source LLMs quickly and inexpensively with 100% privacy-safe Nurdle data.
This example by AnyScale shows performance differences for a specific task (summarizing emails) before and after task-specific fine-tuning.
Train open-source LLMs quickly and inexpensively with 100% privacy-safe Nurdle data.

Why Nurdle?
Methodology
1. Dataset Generation
We generated a dataset consisting of 5,000 rows of customer-specific data. This dataset was carefully crafted to capture the diverse range of language patterns and topics relevant to our customer's needs.
2. Fine-Tuning and Comparison
We utilized NurdleGPT, a second-generation Lookalike Data generator, along with two first-generation synthetic data generators, to create datasets for comparison. Additionally, we used a subsampled dataset of 5,000 rows for fine-tuning purposes.
3. Evaluation
Our evaluation process involved analyzing the results for precision and recall with experienced data labeling teams. We also employed metrics such as Self-BLEU scores and Earth Mover's Distance (EMD) to assess the diversity and distribution matching of the generated data.
4. Cost Analysis
Finally, we conducted a cost analysis to compare the expenses associated with each approach. This included estimating the cost per 5,000 rows of synthetic data generated by different models.
We generated a dataset consisting of 5,000 rows of customer-specific data. This dataset was carefully crafted to capture the diverse range of language patterns and topics relevant to our customer's needs.
2. Fine-Tuning and Comparison
We utilized NurdleGPT, a second-generation Lookalike Data generator, along with two first-generation synthetic data generators, to create datasets for comparison. Additionally, we used a subsampled dataset of 5,000 rows for fine-tuning purposes.
3. Evaluation
Our evaluation process involved analyzing the results for precision and recall with experienced data labeling teams. We also employed metrics such as Self-BLEU scores and Earth Mover's Distance (EMD) to assess the diversity and distribution matching of the generated data.
4. Cost Analysis
Finally, we conducted a cost analysis to compare the expenses associated with each approach. This included estimating the cost per 5,000 rows of synthetic data generated by different models.
Methodology
1. Dataset Generation
We created datasets with NurdleGPT and ChatGPT, each comprising 5,000 rows of synthetic text data, aiming to mimic real human-to-human communications.
2. Text Structure Analysis
We assessed the text structure similarity to human-generated text by analyzing the output of both models, considering shortcuts, punctuation, misspellings, slang, emojis, and overall clarity.
3. Comparison Metrics
We used metrics like Self-BLEU scores and Earth Mover's Distance (EMD) to gauge the resemblance between synthetic data from NurdleGPT and ChatGPT and real human-generated text, aiming for lower Self-BLEU scores and closer EMD values to the gold standard.
4. Cost Analysis
We also compared the expenses of generating synthetic data using NurdleGPT versus ChatGPT, factoring in input/output token costs and the total cost per 5,000 rows of synthetic data.
We created datasets with NurdleGPT and ChatGPT, each comprising 5,000 rows of synthetic text data, aiming to mimic real human-to-human communications.
2. Text Structure Analysis
We assessed the text structure similarity to human-generated text by analyzing the output of both models, considering shortcuts, punctuation, misspellings, slang, emojis, and overall clarity.
3. Comparison Metrics
We used metrics like Self-BLEU scores and Earth Mover's Distance (EMD) to gauge the resemblance between synthetic data from NurdleGPT and ChatGPT and real human-generated text, aiming for lower Self-BLEU scores and closer EMD values to the gold standard.
4. Cost Analysis
We also compared the expenses of generating synthetic data using NurdleGPT versus ChatGPT, factoring in input/output token costs and the total cost per 5,000 rows of synthetic data.
How Nurdle can help
Cold Start Datasets
Get your project off the ground with the custom dataset you need to start model building and iteration.
No data? No problem. If you can specify what you need we can make it.
You’ve got data... but who can afford to clean and label it? Problem solved.
Got lots of data but notallowed to use it? Nurdle data mimics yours and is 100% privacy-compliant.
Startups
Small & Medium Sized Businesses
Enterprise & Regulated
Fine-tuning chatbots for brand or character voice
Improve your customer chatbot experience with diverse datasets to cover edge-cases and persona-based voices synthetically created from billions of real conversations.
Get persona-specific message datasets to tune your product’s voice quickly.
Fine-tune sales and support chatbots based on terrabytes of real marketplace interactions for better performance.
Use 100% privacy-safe conversational data to fine tune generative AI applications without compliance risk.
Startups
Small & Medium Sized Businesses
Enterprise & Regulated
Fine-tuning for semantic search & RAG improvement
Understand what users are looking for even when they’re not sure how to describe it correctly.
Help your chatbots understand a wider variety of search queries so they can respond better.
Help employees find internal documents easier by fine-tuning your model with plain-langage queries.
Embed industry and company expertise into your private chatbot or genAI applications to get better responses.
Startups
Small & Medium Sized Businesses
Enterprise & Regulated
Fine-tune your own private open source LLM
Running a small LLM that performs a specific task well is far less expensive than paying inference costs on large, general-purpose LLMs. Nurdle can provide the data needed to train it.
Instruction Tuning data that reduces Evaluation time and cost
Reduce expensive API calls at inference by fine-tuning your model with a variety of input/output pairs that more closely resemble human instructions.
Reinforcement Learning faster, cheaper and with more control
New techniques show that RLAIF can achieve the same performance as RLHF without the high cost and project delays of human-created preference pairs. Get synthetically-generated preference pairs on demand from Nurdle allows you to customize datasets to avoid naturally-occurring issues such as subjective opinions, suggesting competitors, making deals or discounts for a customer that are invalid, etc.
Data Gap Analysis
Find out what data you're missing for better performance.
If you're not sure what data you need for improvement, Nurdle can analyze your data for you.
If you're not sure what data you need for improvement, Nurdle can analyze your data for you.
Industry Use Cases
Banking, Insurance & Finance
Healthcare
Social Media & Messaging
Dating & Lifestyle
Consumer Brands
AI & SaaS Products
AI Consultancies & Agencies
Trust & Safety Providers
Social Media Monitoring & Insights
Marketplace & Ecommerce
Gaming
Sales & Support Services
How we do it
We produce high volume lookalike data (labeled or not); use your data to test it
Nurdlized Datasets
We produce high volume lookalike data (labeled or not); use your data to test it
Nurdlized Datasets
We detect ideal data clusters and what data is missing for your use-case
Data Gap Analysis
We detect ideal data clusters and what data is missing for your use-case
Data Gap Analysis
We compare yours with our pre-labelled LLM data vault
Nurdle Data Overlay
We compare yours with our pre-labelled LLM data vault
Nurdle Data Overlay
Yours or ours - as few as 50 rows
Real Data Sample
Yours or ours - as few as 50 rows
Real Data Sample
We produce high volume lookalike data (labeled or not); use your data to test it
Nurdlized Datasets
We detect ideal data clusters and what data is missing for your use-case
Data Gap Analysis
We compare yours with our pre-labelled LLM data vault
Nurdle Data Overlay
Yours or ours - as few as 50 rows
Real Data Sample
Need help with something else?
Let Nurdle do the boring part of data science so you can do something more important.
Data Sourcing, Cleaning, Prep & Labeling
Get 100% privacy-compliant custom datasets for specific use-cases, behaviors, text formats and languages.
Classifier Data: Intent & Behavior Detection

Justin Davis
Co-Founder and CEO
"Nurdle has been used for 6 years by Spectrum Labs to parse billions of online human interactions.
We've used Nurdle data to moderate content for Riot Games, Grindr, The Meet Group, Together Labs, and other gaming, dating, and social media platforms."
We've used Nurdle data to moderate content for Riot Games, Grindr, The Meet Group, Together Labs, and other gaming, dating, and social media platforms."






Apply for Nurdle’s Free Pilot Program
Available for a select group of companies.



Data Gap Analysis Report
Preparation of Unstructured Datasets
Augmenting Existing Data into Fine-Tuning Datasets
Identify what kind and how much data is missing from your dataset to increase the accuracy of your LLM.
PII scrubbing for GDPR and HIPPA compliance, cleaning, and labeling.
Use cases include (but are not limited to) conversational LLMs, Q&A LLMs, and training your LLM in multiple languages.
Follow us on social


